Kubernetes Workload Sizing: What We Have and What We Need
Kubernetes workload sizing remains a challenge even with tools like VPA, and is further amplified by Karpenter and KEDA. In this blog we will dive into what current solutions provide and what we truly need to size workloads to ensure stability while not bloating our cloud bill.
Shir Monether
CTO & co-founder
Share
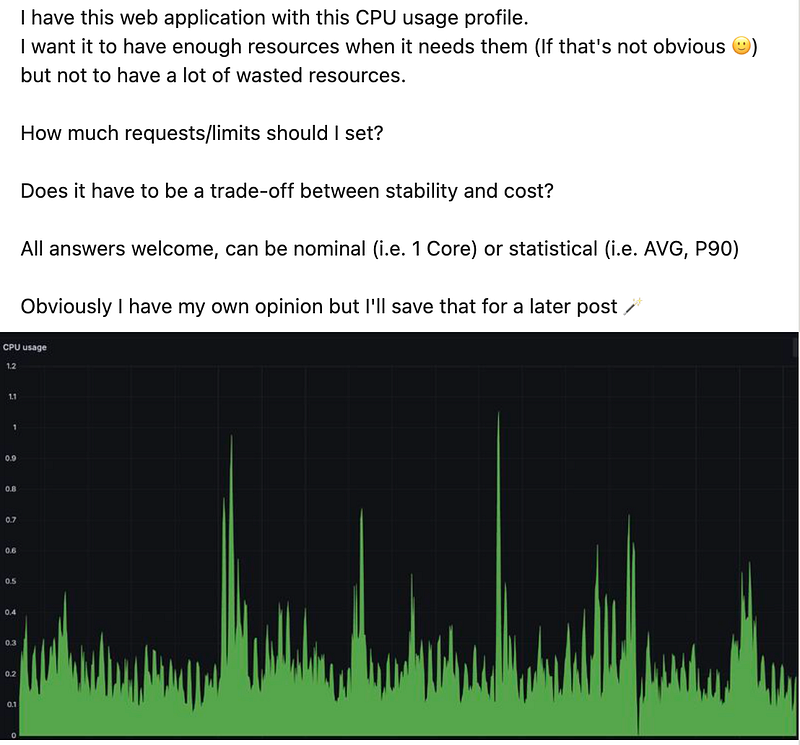
I recently posted a LinkedIn challenge called “Size me this workload”
Starting with a baseline environment that already has Karpenter and KEDA implemented, I got some great answers!
Many suggested “KEDA should do the trick,” “Use VPA,” or “Configure a percentile depending on your SLA.”
But nothing bulletproof.
Even after implementing Karpenter and KEDA, we still need to manage our workload requests to make them as optimal as possible. In fact, improved bin-packing by these solutions increases the criticality, as prior to bin-packing we had more wasted resources acting as an unintentional safety net.
With current solutions we face several critical problems that lead to both instability and wasted resources.
Problem 1: The Invisible Workload Problem
When we don’t have proper workload definitions, Pods from the same logical workload (like Spark jobs or CI/CD runners) are treated as independent entities. This means:
We can’t understand patterns across the entire workload over time
We miss optimization opportunities that only become visible at the workload level
We can’t properly size for workloads that have complex, multi-Pod behaviors
Problem 2: The Runtime Blindness Problem
Without runtime awareness, we treat all containers the same, ignoring that different runtimes have fundamentally different resource behaviors:
JVM applications that dynamically adjust heap based on limits
Go applications with garbage collection patterns
Node.js applications with memory allocation
Take JVM as an example: by default, it allocates 25% of its available memory (limits) to heap space. When we lower the limit, the heap space shrinks proportionally, which can trigger Java out-of-memory kills.
Setting limits without understanding these behaviors can lead to unexpected OOMKills or degraded performance.
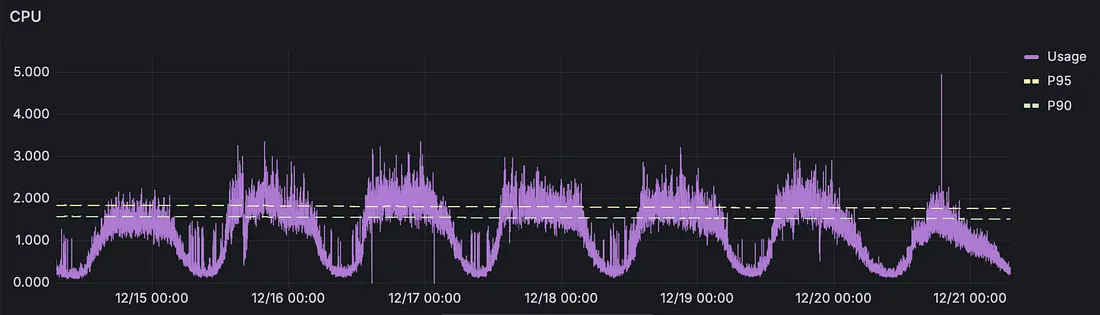
Problem 3: The Percentile Trap
Traditional sizing tools force us to pick a percentile e.g. P90, P95, P99 without understanding what happens during the remaining percentage of time or how severe those peaks actually are (the next evolution of guesswork!).
This creates a double-edged problem:
We either size for the peak and waste money 95%+ of the time
Or we size for the P95 and crash during the 5% of time when we need resources most
Even worse, If the peak is way higher than the baseline, I’m in serious trouble.
Workload that peaks <1% of the time
This is especially problematic because peaks often correlate with business-critical moments — exactly when we can least afford instability. We’re making financial and stability decisions based on incomplete information about both typical usage and burst patterns.
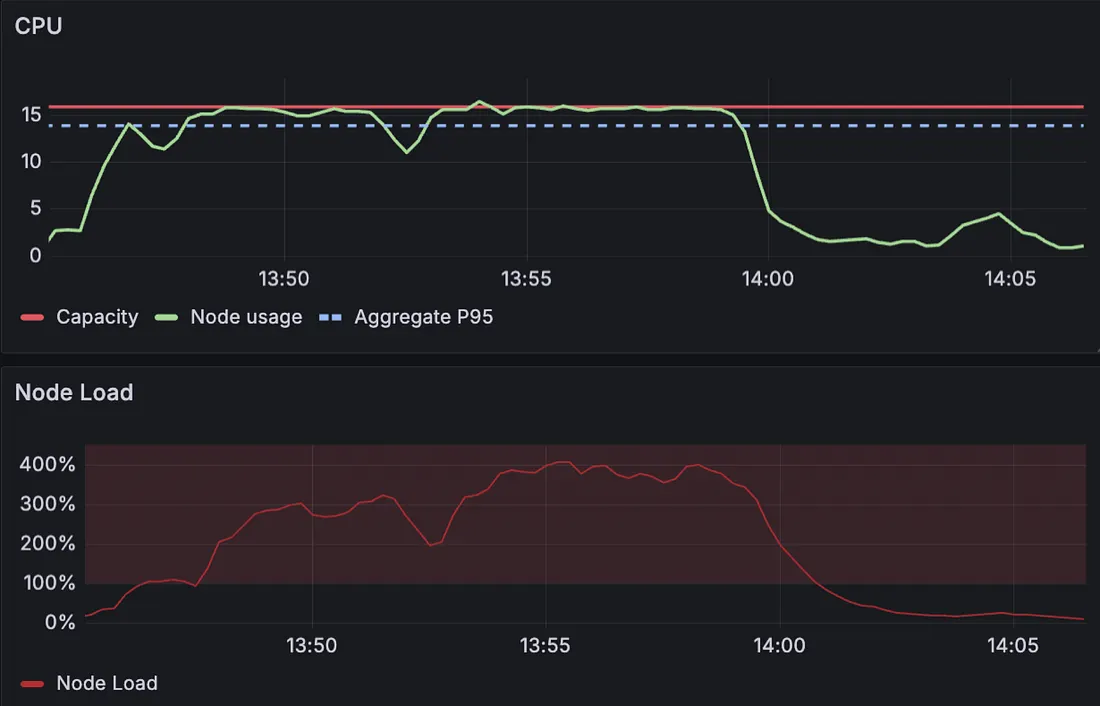
Problem 4: The Isolation Illusion
Optimizing each workload in isolation ignores the reality that they share infrastructure. With this in mind:
We can’t be sure to prevent noisy neighbor scenarios before they happen
We miss opportunities to pack complementary workloads together
We over-provision at the cluster level because we don’t understand actual node utilization patterns
Overloaded Node, Even with P95 requests configured!
These problems compound on each other. A lack of context in one area forces conservative decisions in others, leading to a cascading effect of waste and risk throughout the cluster.
We need a Context-Aware Sizing System
Workload Definition
We need a system that knows how to group these Pods together to understand and define how the workload behaves.
Runtime awareness
We need a system that can understand different runtimes and how they interact with the sizing configurations and size accordingly.
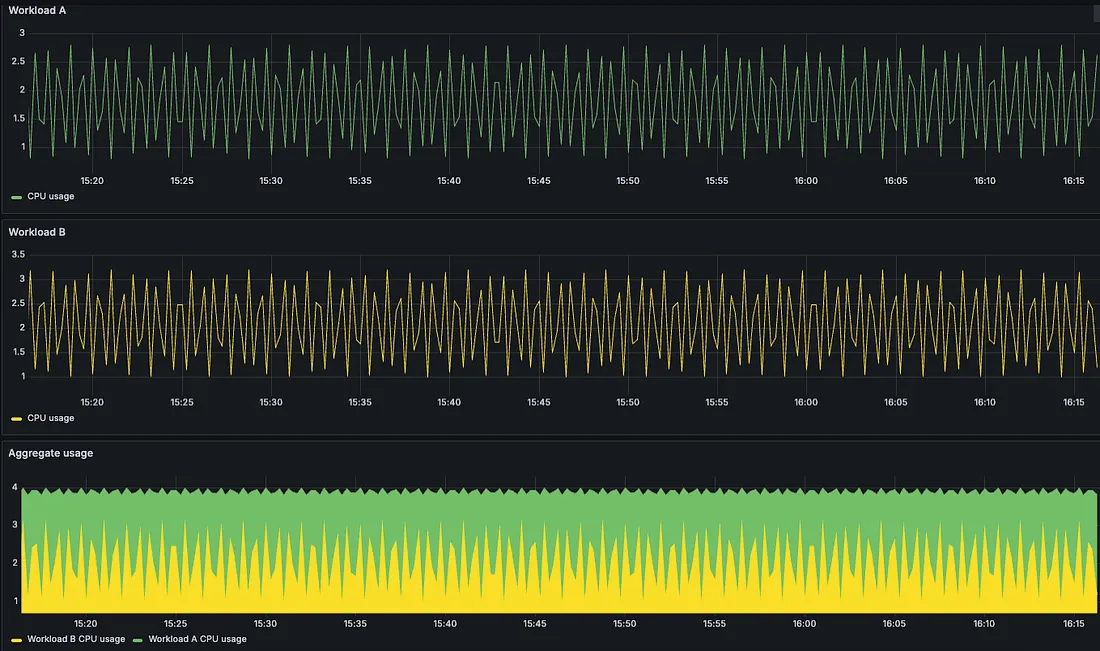
We need to be Node-centric, calculating how workloads perform as a group rather than individually. This lets us identify when workloads peak together and when they have oscillating patterns.
As for workloads with oscillating patterns, we may not need to allocate for peak usage at all, since individual usage patterns can complement one another which compounds with economy of scale.
Complementary Workload usage patterns
Summary
Kubernetes workload sizing remains a challenge even with tools like VPA, and is amplified by Karpenter and KEDA.
Current solutions rely on simple percentile-based approaches that don’t account for critical factors such as workload bursts, runtime behaviors and node-level resource dynamics.
To truly optimize resource allocation, we need context-aware systems that understand workload definitions across different controllers, recognize runtime-specific requirements, account for burst patterns that occur during peak demand, and take a node-centric approach that considers how workloads interact as a group rather than in isolation.
This shift from guesswork to intelligent, context-driven sizing is essential for balancing stability and cost-efficiency in Kubernetes environments and is exactly what we are building at Wand Cloud, If you’d like to see how this works for your environment, schedule a demo to explore optimization without the guesswork.
Related Posts
Sizing
4
min read
“Right-Sizing” in K8s is WRONG.
“Right-sizing” sounds… well, right - give each service exactly what it needs. In reality, it’s a constant trade-off between waste and risk - and when that balance tips, performance slows, availability falters, and costs rise, often all at once.